Bilateral Neural Operators
Learning sequential image enhancement in bilateral space.
| Codes available at: https://github.com/bznick98/bilateral-image-enhance |
| Report available at: Learning Sequential Image Enhancement in Bilateral Space |
Problem Statement
Image enhancement is the process of making changes or improvements to a photograph to enhance its appearance. The inputs are usually low-quality or raw images (e.g. low-light, color-distorted or unprocessed raw sensor data), and preferably outputs a visually pleasing high-quality image for display. Most of the essential steps when human photographer enhances the image includes exposure correction, color style adjustment and white balance correction, etc.
| Input Image | Result |
|---|---|
 |
 |
 |
 |
Image enhancement is not only useful for photographic purposes, but also helps down-stream computer vision tasks like object detection and face recognition.
Existing Methods
There are numerous existing methods ranging from traditional image processing techniques like histogram equalization, and more recent approaches based on deep learning. In this context, our emphasis lies on the deep learning methods due to their superior capabilities and broader applicability.
Bilateral-Grid Based Method
Bilateral grid comes from the paper HDRNet. It is a data structure that represents an image transformation. Comparing to processing full resolution image, processing in bilateral space is faster and edge-aware. A bilateral grid is predicted using downsampled image (thus faster), and final output is sliced from the predicted grid using the full-res image, without the need to feed the full-res image into neural network. Because of this, it consumes less memory space compared to other methods processing using full resolution image.
GAN Based Method
GAN-based approaches like Pix2Pix are indeed highly effective for tasks such as image generation and style transfer. However, one limitation is their tendency to produce images with visible artifacts, resulting in a lack of visual smoothness. This drawback makes them generally unsuitable for applications in photography where high-quality results are required. Furthermore, generative models, including Pix2Pix, often have large model sizes that hinder real-time performance, making them less practical for certain real-time applications.
3D-LUT Based Method
LUT-based approaches, such as AdaInt and 3D-LUT, provide a fast and visually smooth method for image enhancement. These approaches utilize 3D Look-up Tables (LUTs) to efficiently transfer colors from one color space to another. The learned LUTs serve as a compact representation of color transfer, similar to bilateral grids. However, one limitation of 3D LUT-based methods is their lack of interpretability regarding how the model modifies the photo. Additionally, these methods often have relatively larger model sizes compared to Neural Operators.
Sequential Retouching Method
Neural Operator is an innovative approach for image enhancement that aims to mimic the sequential processing performed by human photographers. By learning to apply operators in a sequential manner, the model gains interpretability, allowing users to understand the image processing steps. The trend of performing image restoration tasks in a stage-by-stage fashion has been observed in recent papers, including works like HINet and MAXIM. These approaches adopt a multi-stage architecture, where each stage focuses on addressing specific aspects of the restoration process. However, it’s worth noting that the original Neural Operator implementation may encounter runtime performance issues when dealing with large input images. Processing larger images could potentially result in slower execution times or resource limitations.
Proposed Method
Rather than relying on a black-box image transformation approach, adopting a more interpretable solution similar to the Neural Operator is a viable approach for tackling the image restoration task. By applying sequential operations to the input image, the restoration process can be broken down into stages, allowing for better interpretability and control over the transformation. To mimic how human photographers edit photos, the intermediate operators can be constrained to approximate common photographic operations such as exposure correction, black clipping, vibrance adjustment, white balance adjustment, and more. This approach not only provides a clearer understanding of how the image is being modified but also allows for fine-grained adjustments to achieve the desired restoration outcome.
The original Neural Operator method has shown impressive results on the MIT-Adobe 5K dataset while maintaining a relatively small model size. However, its model architecture directly operates on the full-resolution image, leading to a constraint on the input image size. This limitation becomes particularly challenging when dealing with high-resolution inputs. (e.g. 4K)
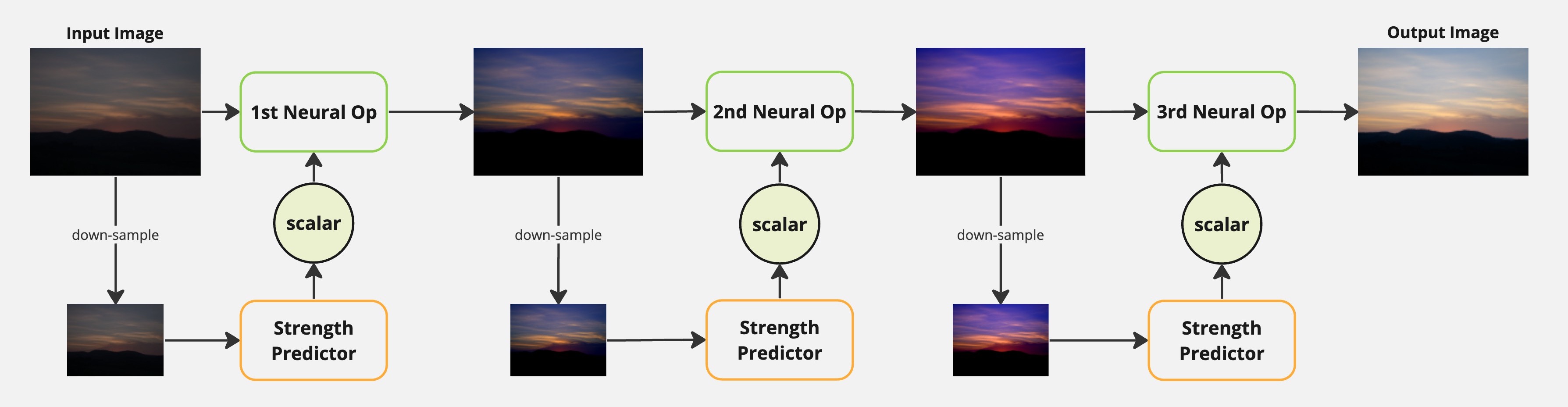
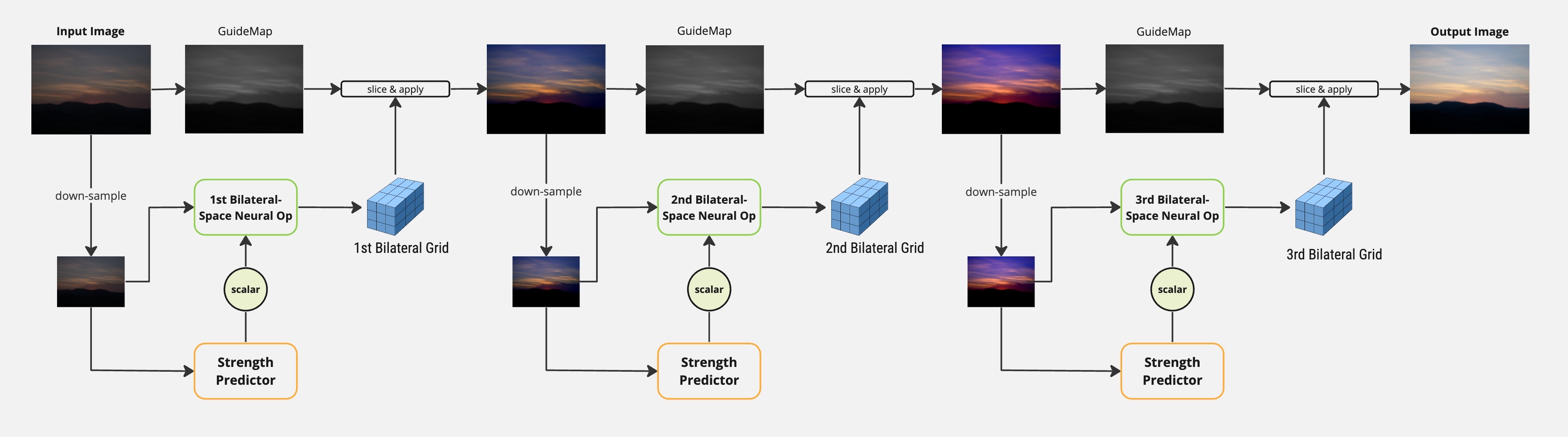
To address the challenge of processing high-resolution images in the original Neural Operator method, one possible approach is to replace each neural operator with a modified lightweight HDRNet. This alternative method avoids processing the full-resolution image “in network.” Instead, it initially operates on a significantly down-sampled version of the image, reducing the computational burden. The full-resolution image is only processed when applying the color transformation (slicing), which is a relatively low-cost operation and less dependent on the input resolution. By adopting this strategy, the computational and memory requirements for processing high-resolution images can be alleviated, making the method more practical and efficient.
A more detailed description of propsed model architecture that combines both the advantages of Neural Ops and HDRNet can be found in the next section.
Model Architecture
Our model uses multi-stage network architecture like Neural Ops, where it solves the image restoration problem step by step. For each stage, it learns a bilateral grid for input/output color transformation. The benefit of using bilateral grid instead of using sets of convolution layers is that bilateral grid is less dependent to full input resolution.
For a single stage, it first downsizes the input resolution to a low-res image (e.g. 3x256x256), and uses low-res image to predict a 8x64x64 bilateral grid. Each cell in this grid contains the slope and bias for corresponding local affine color transformation. For full resolution input, we predict guidemap with a same spatial dimension for slicing through the learned grid. Slice operation will return a full resolution output and we can feed the output to the next stage if needed.
Dataset
A commonly used dataset for evaluating image enhancement process is MIT-Adobe-5K. This dataset consists of 5,000 raw images in 16-bit TIFF format. In order to make a fair comparison with the Neural Ops paper, we decided to use the exact processed dataset they used, which was originally provided by CSRNet (referred to as FiveK-Dark).
For training set, the Neural Ops paper selected 4,500 images from the dataset, while the remaining 500 images were reserved for testing. All the images in the dataset were cropped to a resolution of 500x300 or 300x500, depending on the orientation of the image. The training images are in the format of 16-bit TIFF raw files, while the target images are in 8-bit sRGB JPEG format.
Additionally, we intend to evaluate our models on low-light image datasets such as LOL and VE-LOL. In these datasets, the input images are captured under low-light conditions, while the corresponding target images are high-quality images with correct exposure.
Loss Function
We experimented numerous loss functions for model training, ranging from classical L1/L2 loss to recently proposed SSIM-L1 and Deep Histogram Match Loss. Our experimentations shows that SSIM-L1 helps model achieve superior results in terms of intensity, while Deep Histogram Match Loss helps achieve great color consistent results than simply using L1 loss.
Qualitative Results
We evaluated our method along with the results from the paper NeuralOps. To be fairly compared with Neural Ops, we used our own initialization dataset instead of the one provided by them for evaluating their model (marked as NeuralOps*). We also reported their claimed performance for reference. Detailed quantitative image metric reports are shown in the table below. The reason that there is a gap between the reproduced result and the officially claimed results is that they did not provide the full initialization dataset (only half was provided). All other methods are reported as-is from the NeuralOps paper.
| Model | PSNR | SSIM | ΔE | LPIPS | #params |
|---|---|---|---|---|---|
| White-Box | 18.59 | 0.797 | 17.42 | - | 8,561,762 |
| Distort & Recover | 19.54 | 0.800 | 15.44 | - | 259,263,320 |
| HDRNet | 22.65 | 0.880 | 11.83 | - | 482,080 |
| DUPE | 20.22 | 0.829 | 16.63 | - | 998,816 |
| MIRNet | 19.37 | 0.806 | 16.51 | - | 31,787,419 |
| Pix2Pix | 21.41 | 0.749 | 13.26 | - | 11,383,427 |
| 3D-LUT | 23.12 | 0.874 | 11.26 | - | 593,516 |
| CSRNet | 23.86 | 0.897 | 10.57 | - | 36,489 |
| NeuralOp (from paper) | 24.32 | 0.907 | 9.795 | 0.045 | 28,108 |
| NeuralOp (reproduced) | 24.04 | 0.898 | 10.333 | 0.048 | 28,108 |
| BilateralOp (ours) | 24.22 | 0.906 | 9.830 | 0.043 | 69,012 |
We also measured runtime and memory consumption for Neural Operator and our method Bilateral Operator. The table below shows that our methods achieves similar image enhancement results while maintaining a much smaller memory consumption and faster inference speed, allowing for higher resolution input and more potential on mobile devices.
| Model/Resolution | 500x300 | 1200x900 | 2500x1200 | 4000x3000 |
|---|---|---|---|---|
| NeuralOp | 8.26 ms (121 FPS) 262 MB |
44.41 ms (22 FPS) 1.61 GB |
121.14 ms (8 FPS) 4.43 GB |
N/A N/A |
| BilateralOp (ours) | 6.78 ms (147 FPS) 55 MB |
32.86 ms (30 FPS) 266 MB |
87.05 ms (11 FPS) 702 MB |
350.22 ms (2 FPS) 2.70 GB |
We can see from the table that our method is faster than the Neural Op, and it is able to handle large input resolution and consumes relatively smaller memory space.
Visual Results
To make it easier to understand the strengths and weaknesses of the model, we show the visualization of our model for randomly selected four scenes in figure below. The images are displayed from left to right, starting with the input image, followed by the output image, the target image, and the L2 difference between the output and target images.
By examining these visuals and analyzing our measurements, we find that our model produces excellent results in terms of structural similarity (SSIM). However, there are occasional instances where the colors in the output image differ from the target image, which cannot be fully captured by the SSIM metric alone.
Scene 1


Scene 2


Scene 3


Implementation & Training
The model is implemented in PyTorch with a style similar to Neural Operators, utilizing a yaml configuration system to maintain each experiment setting.
For MIT-Adobe-5K dataset, we used two-phase training strategy. In the Phase-I, only the bilateral neural operators are trained individually by randomly selecting pairs of enhanced image with the corresponding value. Given intensity values and desired outputs, our model is trained to reproduce the results as much as possible. In the Phase-II, we incorporated an encoder and a operator intensity predictor for each pre-trained bilateral operator and jointly train them together.
We used Adam Optimizer with 10e−8 weight decay, 0.9 beta1 and 0.99 beta2, using batch size of 1 trained 400 epochs for Phase-I and 134 epochs for Phase-II.
Conclusion
In our study, we conducted an investigation into various model designs with the goal of enhancing the efficiency of the Neural Operator, a sequential image retouching method. Through our efforts, we successfully achieved competitive results, demonstrating faster runtime and reduced memory consumption compared to previous approaches. However, further work is needed to refine operator initialization schemes to better overcome color shifts problem in our results. For example, during Phase-II training, we could design specific losses for each operator’s output, makeing them to closely approximate the image operators in Adobe Lightroom. Overall, this work contributes by reviewing recent methods, introducing a novel model architecture, and improving the efficiency of the Neural Operator for more practical and more accurate image enhancement.
References
Please see pdf report for references.